
1. Prûˋsentation du projet▲
1-1. Le contexte thûˋorique du projet ▲
La majoritûˋ des applications sur Internet sont accessibles via le protocole HTTP. Ces applications sont hûˋbergûˋes sur des serveurs Web. Cependant avec lãaugmentation du nombre dãutilisateurs de ces applications, le temps de rûˋponse aux requûˆtes des clients devient assez important. Rûˋpondre efficacement aux requûˆtes des utilisateurs nûˋcessite le dûˋploiement de plusieurs serveurs Web sur plusieurs machines (un cluster de machines). Les machines du cluster peuvent avoir des caractûˋristiques diffûˋrentes (CPU, RAMãÎ). Au niveau de ce cluster, une machine centrale va recevoir les requûˆtes des utilisateurs et elle va les rûˋpartir sur lãensemble des serveurs. La rûˋpartition doit prendre en considûˋration les caractûˋristiques de chaque serveur afin dãavoir une rûˋpartition ûˋquilibrûˋe (chaque serveur va avoir un nombre de requûˆtes û traiter selon ses caractûˋristiques).
1-2. La description du projet ▲
Lãopûˋration de lãorientation des nouveaux bacheliers se dûˋroule chaque annûˋe. Le nombre de bacheliers ne cesse dãaugmenter chaque annûˋe, ce qui engendre un accû´s de plus en plus intense aux serveurs (notamment dans la pûˋriode de lãannonce des rûˋsultats de lãorientation). Pour faire face û ce problû´me, les responsables ont mis en place un cluster de serveurs Web. Un logiciel est utilisûˋ pour rûˋpartir les requûˆtes sur les diffûˋrents serveurs. Chaque annûˋe, de nouveaux serveurs physiques sont acquis et actuellement le cluster est constituûˋ dãun ensemble de serveurs ayant diffûˋrentes caractûˋristiques. Le logiciel utilisûˋ ne prend pas en compte lãûˋquilibrage de charge, alors chaque serveur va avoir la mûˆme charge (nombre de requûˆtes) ce qui va crûˋer un dûˋsûˋquilibre dans la rûˋpartition des requûˆtes. Pour exploiter efficacement les serveurs, ils pensent mettre en place un cluster de serveurs Web avec un ûˋquilibrage de charge, et donc ont lancûˋ un appel dãoffres pour lãacquisition dãune plate-forme logicielle pour gûˋrer un cluster dãûˋquilibrage de charge. Suite û cet appel dãoffres, ils ont retenu deux offres, la premiû´re est basûˋe sur LVS (Linux Virtual Server) et la deuxiû´me sur Haproxy. Ils ont donc fait appel û vous pour les aider û choisir la meilleure offre.
On vous demande de rûˋpondre û cet appel dãoffres en dûˋployant les deux outils et en effectuant une sûˋrie de tests de performance pour choisir le meilleur outil.
1-3. Objectifs du projet▲
-
Dûˋployer le clusterô :
- Donner la description dûˋtaillûˋe des ûˋtapes du dûˋploiement (installation et configuration) du cluster (dûˋploiement de LVS et Haproxy).
-
Effectuer des tests fonctionnels (LVS et Haproxy).
-
Lãûˋvaluation des performances du cluster et ûˋtude comparativeô :
- Effectuer une sûˋrie de tests de performance pour ûˋvaluer les performances du cluster (LVS et Haproxy).
- Selon les rûˋsultats, faire une ûˋtude comparative entre LVS et HaProxy.
Quelques exigences techniquesô :
En plus de LVS et Haproxy, on vous demande de dûˋployer les logiciels suivantsô :
- Gangliaô : un outil de supervision dûˋdiûˋ au cluster. Ganglia va permettre de visualiser lãûˋtat du cluster (consommation des ressources au niveau de chaque néud du cluster).
- NTPô : un serveur de temps pour synchroniser entre les néuds du cluster.
- SSHô : accû´s distant au cluster et communication entre les néuds du cluster.
Il est aussi exigûˋ dãutiliserô :
- Apache comme serveur Webô ;
- CentOS comme distribution Linuxô ;
- machines virtuelles pour la mise en place du clusterô ;
- VirtualBox pour la virtualisation.
Pour lãoutil dãûˋvaluation des performances, vous pouvez utiliser soit lãutilitaire ab (Apache benchmark) ou lãoutil Apache-Jmeter. Serveurs Web sur plusieurs machines (un cluster de machines). Les machines du cluster peuvent avoir des caractûˋristiques diffûˋrentes (CPU, RAMãÎ). Au niveau de ce cluster, une machine centrale va recevoir les requûˆtes des utilisateurs et elle va les rûˋpartir sur lãensemble des serveurs. La rûˋpartition doit prendre en considûˋration les caractûˋristiques de chaque serveur afin dãavoir une rûˋpartition ûˋquilibrûˋe (chaque serveur va avoir un nombre de requûˆtes û traiter selon ces caractûˋristiques).
Nous avons choisi d'utiliser Ganglia.
2. Dûˋploiement du cluster ã description technique▲
2-1. Introduction▲
Avant, le contenu Web ûˋtait en majeure partie statique et donc trû´s facile û dûˋlivrer rapidement aux clients, mais aujourdãhui, le contenu des pages Web est devenu principalement dynamique, permettant lãinteraction entre lãutilisateur et les services offerts, et induisant une forte charge sur les serveurs Web tout en exigeant des rûˋponses rapides, une haute performance ainsi quãune disponibilitûˋ permanente des applications. Pour cela, les applications Web doivent ûˆtre en mesure de fonctionner sur plusieurs serveurs Web de maniû´re û exploiter pleinement leur performance et cela dans le but de supporter lãaccroissement dynamique et soudain du nombre de clients et donc de requûˆtes, grûÂce û des mûˋcanismes de scalabilitûˋ, rûˋpartition de charge et haute disponibilitûˋ. Dans le cas de notre projet, ceci se fera û travers la mise en place de deux principaux outilsô : LVS (Linux Virtual Server) et HAProxy (High Availability Proxy).
2-2. HAProxy▲
2-2-1. Description▲
HAProxy est une solution open source trû´s flexible offrant des fonctionnalitûˋs de rûˋpartiteur de charge, reverse proxy HTTP et proxy TCP (cãest-û -dire quãil fonctionne aussi bien sur la couche 4 que sur la couche 7 du modû´le OSI) ainsi que des services de haute disponibilitûˋ (HA). Il est utilisûˋ gûˋnûˋralement dans le cas dãun fort trafic et cãest dãailleurs lãune des raisons pour laquelle il est utilisûˋ par plusieurs grands sites Web, notamment GitHub, Instagram, Twitter, Stack Overflow, Reddit, Tumblr, Yelp et tant dãautres.
2-2-2. Fonctionnalitûˋs▲
- Rûˋpartition de charge û lãaide de plus de neuf algorithmes dãordonnancement. Ceci permet de router les requûˆtes ûˋmanant de diffûˋrents clients vers les serveurs de backend de maniû´re û ce que la charge soit ûˋquilibrûˋe au mieux et en ûˋvitant toute surcharge sur les serveurs pour permettre un service de qualitûˋ rapide et performant. Ceci se fait selon deux modesô : le mode TCP et le mode HTTP.
- Proxy TCP permettant de relayer le trafic entre le client et le serveur en rattachant la connexion ouverte avec le client au serveur pour faire passer le trafic, il joue donc le rûÇle dãintermûˋdiaire entre les deux.
- Proxy inverse HTTP, appelûˋ aussi passerelle ou gateway, dans ce cas HAProxy joue le rûÇle dãun serveur proxy ouvrant deux connexions diffûˋrentes avec le client et le serveur et fait passer les requûˆtes entre les deux bouts. Lãavantage majeur de ce dernier est de ô¨ô cacherô ô£ des informations sur les serveurs backends.
- Offre des mûˋcanismes assurant la haute disponibilitûˋ afin de garantir la continuitûˋ de service et ceci û travers lãutilisation automatique de serveurs rûˋpliquûˋs en cas de panne par exemple.
- Offre un stack SSL avec ûˋnormûˋment de fonctionnalitûˋs et joue le rûÇle de terminaison SSL, il dûˋcharge donc les serveurs Web de tout ce qui est traitement liûˋ au cryptage/dûˋcryptage SSL/TLS.
- Optimisation des ressources et minimisation du temps de rûˋponse.
- Optimise le trafic et protû´ge les serveurs en ûˋvitant de transmettre toute requûˆte invalide aux serveurs.
- Il offre la possibilitûˋ de continuer û fonctionner normalement mûˆme en cas de panne des serveurs backend.
- Permet de faire du monitoring concernant les serveurs et HAProxy lui-mûˆme.
- Offre la possibilitûˋ de choisir un serveur bien prûˋcis pour lui transmettre la requûˆte et ce, en se basant sur nãimporte quel ûˋlûˋment figurant dans la requûˆte reûÏue. Ceci est particuliû´rement utile pour gûˋrer les sessions des utilisateurs pour quãun utilisateur soit toujours envoyûˋ vers le mûˆme serveur.
- Il offre des services de health checks permettant de vûˋrifier le bon fonctionnement des serveurs backend ainsi que lãûˋlimination de serveurs dûˋfaillants. Ceci se fait û travers un certain nombre de fonctionnalitûˋs de vûˋrification offertes par HAProxy.
- Offre un certain nombre de mûˋtriques pouvant ûˆtre utilisûˋes afin de dûˋterminer les performances et lãûˋtat de lãarchitecture en ûˋvaluant certains critû´res frontend (cãest-û -dire entre HAProxy et les clients) et backend (entre HAProxy et les serveurs), par exemple, il est possible de connaûÛtre le nombre de requûˆtes par seconde, nombre de sessions crûˋûˋes par seconde, nombre dãerreurs HTTP cûÇtûˋ client et cûÇtûˋ serveur, nombre de tentatives de connexion, etc. Ceci a principalement pour but dãanalyser le trafic et prendre des dûˋcisions en cas de problû´me pour amûˋliorer le rendement et les performances.
- Offre la possibilitûˋ dãavoir des connexions chiffrûˋes des deux cûÇtûˋs (client et serveur) avec SSL/TLS.
- Assure un certain niveau de sûˋcuritûˋ en offrant une protection contre les attaques DDoS par exemple en gardant les statistiques de connexions, adresses IP, URL, cookies, etc. pour ensuite appliquer les actions appropriûˋes comme le blocage.
2-2-3. Rûˋpartition de charge avec HAProxy▲
HAProxy offre des fonctionnalitûˋs de rûˋpartition de charge (load balancing) assez complû´tes, dans le sens oû¿ elles permettent de rûˋaliser plusieurs configurations personnalisûˋes et adaptûˋes aux besoins de ses utilisateurs. Il existe deux modes de load balancing offerts par HAProxyô : le mode TCP et le mode HTTP.
2-2-3-1. Mode de load balancingô : TCP▲
Les dûˋcisions de rûˋpartition de charge se font sur la base de toute la connexion. Dans ce cas, lãentûˆte de la requûˆte HTTP nãest pas ûˋvaluûˋ.
2-2-3-2. Mode de load balancingô : HTTP▲
Les dûˋcisions de rûˋpartition de charge se font uniquement sur la base de la requûˆte (chaque requûˆte sûˋparûˋment). Cette mûˋthode permet par exemple de choisir le backend selon lãURL de la requûˆte.
2-2-4. Fonctionnement▲
HAProxy considûˋrûˋ comme deux half-proxy, est composûˋ de deux parties essentielles, la partie frontend qui est directement en contact avec le cûÇtûˋ client et reste en ûˋcoute de ce dernier et la partie backend, du cûÇtûˋ des serveurs. Quand une requûˆte est reûÏue par le frontend de HAProxy û partir dãun client, celui-ci applique alors les rû´gles dûˋfinies û ce niveau telles que le blocage de requûˆtes, modification des entûˆtes ou tout simplement lãinterception de ces derniû´res pour ûˋtablir des statistiques. Les requûˆtes sont ensuite envoyûˋes vers le cûÇtûˋ backend de HAProxy, qui est reliûˋ directement aux serveurs Web oû¿ la stratûˋgie de load balancing est appliquûˋe et que se termine par lãenvoi de la requûˆte vers le serveur choisi. Aprû´s le traitement de la requûˆte par le serveur, sa rûˋponse est transmise û HAProxy qui peut effectuer quelques traitements dessus ou lãenvoyer directement au client via le frontend. Bien ûˋvidemment, HAProxy peut ûˆtre vu comme full-proxy, cãest-û -dire lãunion du frontend et du backend.
|
|
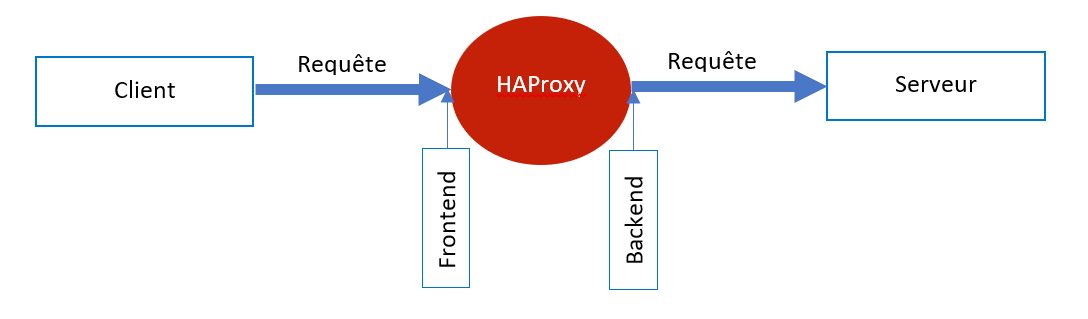
2-2-5. Algorithmes dãordonnancement▲
Plus de neuf algorithmes dãordonnancement sont offerts par HAProxy, nous citons les plus frûˋquents dãusageô :
- Round robinô : cãest le plus communûˋment utilisûˋ, son principe consiste û distribuer les requûˆtes sur les diffûˋrents serveurs un û un en rebouclant. Le RR standard fonctionne de faûÏon ô¨ô automatiqueô ô£ en adressant chaque serveur û tour de rûÇle û la chaûÛne, mais il existe une variante du RR û laquelle on peut ajouter des pondûˋrations dans le cas de serveurs hûˋtûˋrogû´nes afin de bûˋnûˋficier au maximum des performances de chaque néud du cluster.
- Least connectionô : il consiste û dûˋterminer le serveur qui a ûˋtûˋ le plus anciennement utilisûˋ et avec le plus petit nombre de connexions actives afin de lui transmettre la requûˆte.
- Sourceô : se base sur lãadresse IP source du client hachûˋe pour dûˋterminer le serveur auquel envoyer la requûˆte. De ce fait, un client retombera toujours sur le mûˆme serveur qui pourrait ûˆtre une solution quant û la persistance de sessions (mais assez limitûˋe).
- URIô : le serveur sûˋlectionnûˋ dûˋpend directement de lãURI de la requûˆte HTTP. Dans ce cas, on calcule le hachûˋ de lãURI (deux cas possiblesô : la partie gauche de lãURI uniquement (avant le point dãinterrogation, cãest-û -dire avant le passage de paramû´tres) ou alors lãURI entiû´re si elle contient tous les paramû´tres). Cet hachûˋ nous permettra de dûˋfinir le serveur vers lequel envoyer notre requûˆte. Cet algorithme est gûˋnûˋralement utilisûˋ dans le cas de proxy de cache dans le but de maximiser le nombre de ô¨ô hitsô ô£ (accû´s au cache et obtention de la donnûˋe avec succû´s).
- HDRô : se base sur un champ spûˋcifique de lãentûˆte HTTP afin de dûˋterminer le serveur destination.
Remarqueô : les algorithmes de round robin, least connection et les algorithmes û hachage permettent de faire une pondûˋration dynamique des serveurs, ce qui nous offre la possibilitûˋ de changer le poids dãun serveur.
2-2-6. Persistance des sessions▲
HAProxy offre diverses mûˋthodes pour assurer la persistance des sessions appelûˋe aussi ô¨ô Stickinessô ô£, celle-ci peut ûˆtre basûˋe sur divers paramû´tres tels que lãadresse IP source, lãURL, cookies, sessions, etc., afin de dûˋterminer le bon serveur et assurer que le client retombe toujours sur ce dernier et quãil ne soit pas dûˋconnectûˋ û chaque envoi de requûˆte, car il ne tombe pas sur le serveur contenant les informations concernant sa session. Les informations de mapping entre client/serveur sont gardûˋes dans une table au niveau de HAProxy appelûˋe stickiness table, elle contient comme entrûˋe le client et le serveur contentant les informations de ce client.
2-2-7. Haute disponibilitûˋ▲
Les algorithmes dãûˋquilibrage de charge naû₤fs augmentent le risque dãindisponibilitûˋ des serveurs, car ils augmentent la probabilitûˋ quãun client tombe sur un serveur indisponible, il est donc trû´s important de garantir la disponibilitûˋ des serveurs û tout moment aux clients et ûˋviter lãarrûˆt de service. Afin de garantir cela, HAProxy offre des mûˋcanismes permettant la mise en place de la haute disponibilitûˋ. HAProxy permet dãeffectuer des tests pûˋriodiques sur lãûˋtat des serveurs afin de vûˋrifier leur bon fonctionnement û travers ce que lãon appelle les health checks, ainsi une requûˆte est dûˋlivrûˋe û un serveur que sãil est pleinement opûˋrationnel. Il permet aussi de supprimer un néud (serveur) sans affecter le fonctionnement de lãarchitecture globale, sans oublier le fait quãil utilise automatiquement les serveurs backup quand une panne est dûˋtectûˋe, ce qui permet dãavoir un service continu malgrûˋ lãarrûˆt dãun serveur. Par dûˋfaut, les charges sont rûˋparties ûˋquitablement sur le reste des serveurs quand lãun dãeux tombe en panne.
2-3. LVS▲
2-3-1. Description▲
LVS est un projet gratuit et open source lancûˋ par Wensong Zhang en mai 1998, sous licence GNU General Public License (GPL), version 2.
La mission de ce projet ûˋtait de construire un serveur de haute performance pour Linux utilisant la technologie du clustering.
Il est principalement composûˋ de IPVSô : un logiciel dãûˋquilibrage de charge IP implantûˋ dans le noyau Linux.
Le code de LVS est fusionnûˋ dans les versions 2.4.x et plus rûˋcentes du noyau Linux 1.
2-3-2. Load Balancing▲
2-3-2-1. Layer 4 Load Balancing (IPVS)▲
Lãûˋquilibrage de charge au niveau de la couche 4 est implûˋmentûˋ û travers IPVS, celui-ci dirige les requûˆtes aux serveurs du cluster en utilisant lãune des trois techniques de load balancing IP ci-dessousô :
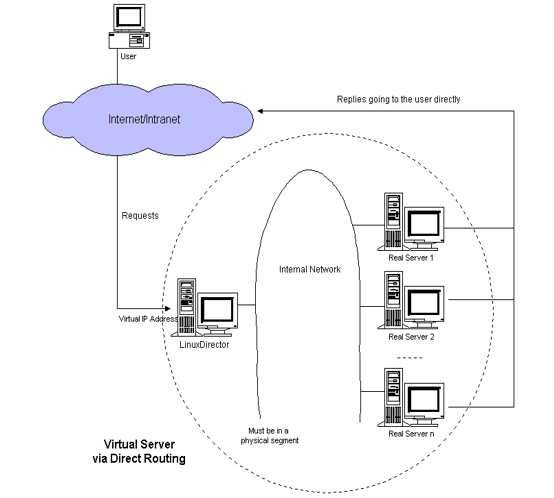
- Direct Routingô :le load balancer et les serveurs du cluster partagent une mûˆme adresse virtuelle. Les requûˆtes des utilisateurs sont envoyûˋes vers le load balancer qui examine lãadresse et le port de destination et vûˋrifie sãils correspondent bien û un des services du cluster. Un algorithme dãordonnancement dûˋcide ensuite du serveur vers lequel la requûˆte est envoyûˋe. Une fois traitûˋe, le serveur envoie une rûˋponse directement au client sans passer par le load balancer (dãoû¿ le nom ô¨ô routage directô ô£). û noter que les serveurs et le load balancer doivent ûˆtre dans le mûˆme rûˋseau local.
|
|
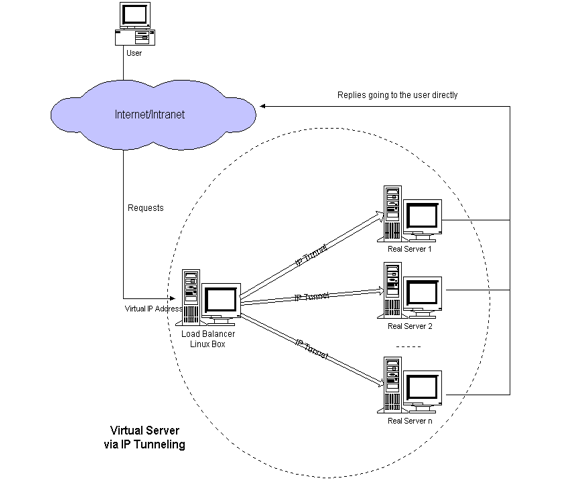
- IP Tunnelingô : cette technique suit le mûˆme principe que le ô¨ô Direct Routingô ô£, sauf que le load balancer et les serveurs peuvent ne pas appartenir au mûˆme rûˋseau local. Un tunnel est alors crûˋûˋ entre eux et les paquets reûÏus par le load balancer sont encapsulûˋs dans des entûˆtes IP et envoyûˋs vers les serveurs.
|
|
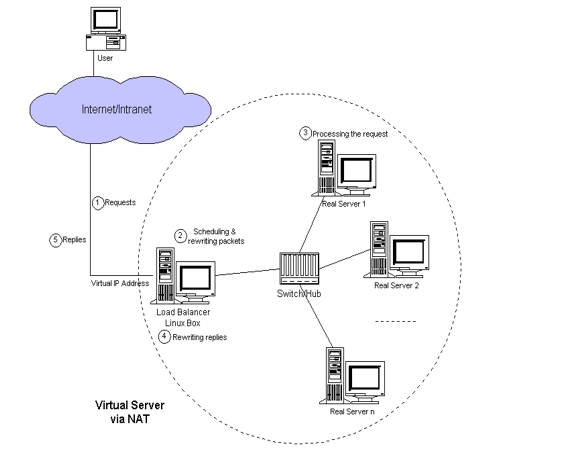
- NATô : lorsque le load balancer reûÏoit les requûˆtes des utilisateurs, il choisit un serveur grûÂce û un algorithme dãordonnancement et lãadresse et le port de destination sont translatûˋs vers ceux du serveur choisi. Une fois la requûˆte traitûˋe, la rûˋponse est renvoyûˋe vers le load balancer qui va remplacer lãadresse et le port source par ceux du load balancer (plus prûˋcisûˋment ceux du service virtuel) pour finalement lãenvoyer û lãutilisateur.
|
|
2-3-2-2. Layer 7 Load Balancing (KTCPVS)▲
Le systû´me KTCPVS redirige les requûˆtes aux diffûˋrents serveurs en se basant sur le contenu de ces derniû´res. Les diffûˋrents composants sont reliûˋs û travers des LAN/WAN.
|
|
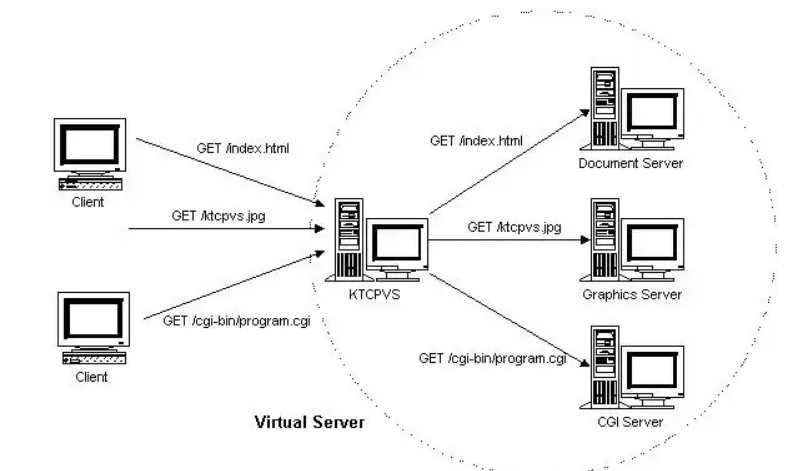
2-3-3. Algorithmes dãordonnancement▲
LVS supporte un grand nombre dãalgorithmes, ils sont listûˋs ci-dessousô :
- Round robinô : les serveurs sont choisis û tour de rûÇle de maniû´re cyclique.
- Weighted round robinô : les serveurs sont choisis û tour de rûÇle, mais relativement û leur poids, cãest-û -dire que les serveurs ayant les poids les plus forts seront dûˋsignûˋs en premier et recevront plus de requûˆtes par rapport û ceux ayant des poids plus faibles.
- Least connectionô : le serveur ayant le moins de connexions (donc le moins chargûˋ) est choisi.
- Weighted least connectionô : le serveur ayant le moins de connexions relativement û son poids est choisi, cãest-û -dire que celui qui minimise le rapport Ci/Wi est dûˋsignûˋ (Avec Ci le nombre de connexions du serveur i et Wi son poids).
- Destination hashingô : lãadresse IP destination est hachûˋe et le choix du serveur se fera selon cette valeur.
- Source hashingô : lãadresse IP source est hachûˋe et le choix du serveur se fera selon cette valeur.
- Locality-based least connectionô : un groupe dãutilisateurs est affectûˋ û chaque serveur (il est choisi en utilisant lãalgorithme du weighted least connection), et si celui-ci nãest pas surchargûˋ, il recevra les requûˆtes des clients qui lui sont attachûˋs. Dans le cas contraire, le serveur qui a un nombre de connexions infûˋrieur û la moitiûˋ de son poids est dûˋsignûˋ.
- Locality-Based least connection with replicationô : cet algorithme suit le mûˆme principe que celui du locality-based least connection, sauf que les groupes dãutilisateurs sont affectûˋs non pas û un seul serveur, mais û un ensemble de serveurs, et dans cet ensemble, un serveur est dûˋsignûˋ en utilisant lãalgorithme du weighted least connection.
- Shortest expected delayô : le serveur ayant le dûˋlai le plus court (estimûˋ selon une formule basûˋe sur le nombre de connexions et le poids) est choisi.
- Never queueô : sãil y a un serveur idle (au repos), il sera choisi, sinon, lãalgorithme du shortest expected delay sera utilisûˋ.
2-3-4. Persistance▲
Il arrive parfois que deux connexions dãun mûˆme client se doivent dãûˆtre attribuûˋes au mûˆme serveur pour des raisons fonctionnelles ou de performance. Par exemple, FTP qui nûˋcessite lãûˋtablissement dãune connexion entre le port 21 du serveur et le port du client ainsi que lãenvoi des donnûˋes û travers le port 22. Le protocole SSL est ûˋgalement un exemple puisquãun ID de session est gûˋnûˋrûˋ pour lãutilisateur, il serait donc intûˋressant de le garder pour des connexions futures.
LVS implûˋmente cette fonctionnalitûˋ en utilisant des ô¨ô templatesô ô£ de connexion. Lorsque lãutilisateur accû´de pour la premiû´re fois au serveur, un template est crûˋûˋ entre cet utilisateur et le serveur qui a ûˋtûˋ choisi avec des informations sur les ports utilisûˋs, et pour chaque connexion, une entrûˋe est gûˋnûˋrûˋe dans une table de hachage au niveau du load balancer. Le template peut expirer dans un dûˋlai configurable, cependant, tant que toutes les connexions correspondant au template ne se terminent pas, il nãexpirera pas.
3. Implûˋmentation▲
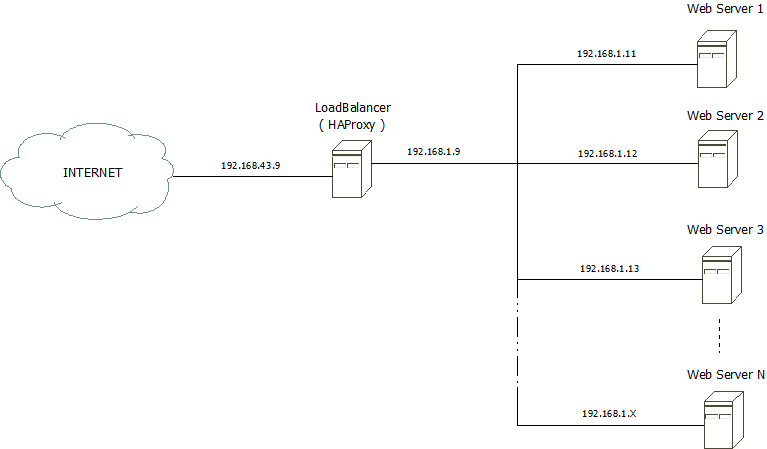
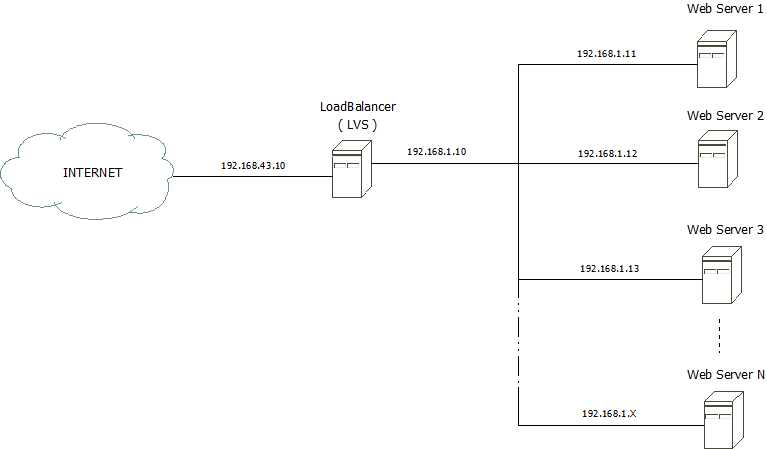
3-1. Mise en place de la plateforme ã topologie▲
|
|
|
|
3-2. Mise en place des serveurs Web▲
3-2-1. Installation de Apache▲
Il suffit dãexûˋcuter la commande suivanteô :
sudo yum -y install httpd
Pour dûˋmarrer le serviceô :
service httpd start3-2-2. Installation de MySQL▲
Il suffit dãexûˋcuter la commande suivanteô :
sudo yum -y install mysql-server mysql-clientPour dûˋmarrer le serviceô :
service mysqld start3-2-3. Installation de SSH▲
Il suffit dãexûˋcuter la commande suivanteô :
sudo yum -y install opensshPour dûˋmarrer le serviceô :
service sshd start3-3. Mise en place de HAProxy▲
Dans cette partie, nous allons dûˋtailler lãinstallation du logiciel HaProxy version 1.7.8.
3-3-1. Installation▲
Tout dãabord, avant lãinstallation de HAProxy, il est nûˋcessaire dãinstaller quelques prûˋrequis pour pouvoir tûˋlûˋcharger et compiler le programmeô :
sudo yum install wget
sudo yum install gcc pcre-static pcre-devel -yEnsuite, on tûˋlûˋcharge la version 1.7.8 de HAProxy avec la commande suivanteô :
wget https://www.haproxy.org/download/1.7/src/haproxy-1.7.8.tar.gz -O ~/haproxy.tar.gz
On compile le logiciel en utilisant les commandes suivantesô :
tar xzvf ~/haproxy.tar.gz -C ~ô
cd ~/haproxy-1.7.8
make TARGET=linux2628
sudo make install
On vûˋrifie que lãinstallation a bien eu lieuô :
haproxy -v
On aô :
HAProxy version 1.7.8 2017/07/073-3-2. Configuration▲
Pour la configuration de HAProxy, tout dãabord il est nûˋcessaire de crûˋer les rûˋpertoires suivants pour les fichiers de configuration et de statistiquesô :
sudo mkdir -p /etc/haproxy
sudo mkdir -p /var/lib/haproxy
sudo touch /var/lib/haproxy/statsOn ajoute un lien symbolique du binaire dãHAProxy dans le rûˋpertoire /usr/sbin pour pouvoir le lancer en tant quãutilisateur normal (Non root)ô :
sudo ln -s /usr/local/sbin/haproxy /usr/sbin/haproxyOn ajoute HAProxy en tant que service systû´meô :
sudo cp ~/haproxy-1.7.8/examples/haproxy.init /etc/init.d/haproxy
sudo chmod 755 /etc/init.d/haproxy
sudo systemctl daemon-reloadOn modifie le fichier de configuration /etc/haproxy/haproxy.cfg avec la configuration suivanteô :
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend http_front
bind *:80
stats uri /haproxy?stats
default_backend http_back
backend http_back
balance roundrobin
server webserver1 192.168.1.11:80 check weight 45
server webserver2 192.168.1.12:80 check weight 20
server webserver3 192.168.1.13:80 check weight 35
Dans lãexemple ci-dessus, lãalgorithme dãordonnancement est le round robin et les poids des serveurs Web sont respectivementô : 45ô %, 20ô % et 35ô %.
3-4. Mise en place de LVS▲
Dans cette partie, nous allons dûˋtailler lãinstallation du logiciel LVS version 1.26.
3-4-1. Installation▲
Avant dãinstaller LVS, il est nûˋcessaire dãinstaller les packages suivants pour pouvoir tûˋlûˋcharger et compiler le source de LVSô :
sudo yum -y install wget gcc pcre-static pcre-devel libnl* popt*
Ensuite, nous allons rûˋcupûˋrer la version 1.26 de LVS destinûˋe au noyau 2.6 de Linux comme suitô :
wget http://www.linuxvirtualserver.org/software/kernel-2.6/ipvsadm-1.26.tar.gzIl suffit maintenant de dûˋcompresser et de compiler LVS en utilisant les commandes suivantesô :
tar -xvf ipvsadm-1.26.tar.gz
cd ipvsadm-1.26
sudo make install
Enfin, il faut activer le IP forwarding afin de pouvoir faire transiter les paquets dãune interface û une autre, pour cela, nous allons modifier le fichier /etc/sysctl.conf comme suitô :
net.ipv4.ip_forward = 1Il ne nous reste plus quãû redûˋmarrer le service et faire en sorte quãil soit automatiquement activûˋ û lãallumage de la machineô :
service ipvsadm restart
chkconfig ipvsadm on3-4-2. Configuration▲
Aprû´s avoir installûˋ LVS sur le load balancer, nous passons maintenant û sa configuration en suivant les ûˋtapes ci-dessousô :
On vide la table ipvsadm en exûˋcutant la commande suivanteô :
# ipvsadm -C
On modifie ensuite le fichier de configuration de LVS /etc/sysconfig/ipvsadm, afin dãy spûˋcifier le load balancer ainsi que les trois serveurs Web que nous avons initialement mis en place. Nous avons choisi comme algorithme WRR (Weighted Round Robin) qui nous permet de dûˋfinir des poids pour chaque serveur (65ô %, 15ô % et 20ô % pour les serveurs Web 1, 2 et 3 respectivement) afin de lui transmettre le taux de requûˆtes quãil peut supporter selon ses performances. Voici le contenu du fichier de configuration de LVSô :
-A -t 192.168.43.9:80 -s wrr
-a -t 192.168.43.9:80 -r 192.168.1.11:80 -m -w 65
-a -t 192.168.43.9:80 -r 192.168.1.12:80 -m -w 15
-a -t 192.168.43.9:80 -r 192.168.1.13:80 -m -w 20Afin que les modifications soient prises en compte, on redûˋmarre le service ipvsadm de la maniû´re suivanteô :
# service ipvsadm restart
On vûˋrifie ensuite, que la configuration a bien ûˋtûˋ prise en charge, en affichant la table ipvsadm comme suitô :
# ipvsadm -lAfin de permettre la communication entre les serveurs Web et le load balancer LVS, on doit dûˋfinir lãinterface interne (cûÇtûˋ serveur) de LVS comme ûˋtant la passerelle par dûˋfaut de ces derniers.
4. Dûˋploiement de NTP▲
4-1. Introduction▲
La notion de temps est critique pour les systû´mes informatiques. C'est la seule rûˋfûˋrence qu'un rûˋseau a pour savoir quand les applications et les processus doivent ûˆtre ou ont ûˋtûˋ faits. La solution pour assurer la synchronisation du rûˋseau est assez simple et relativement peu coû£teuseô : un serveur de temps NTP.
Dans cette partie, nous allons ûˋnumûˋrer les ûˋtapes de dûˋploiement de NTP (Network Time Protocol) permettant dãassurer une synchronisation temporelle entre tous les néuds. On passera ensuite aux ûˋtapes de dûˋploiement de Ganglia pour monitorer notre cluster et enfin, on parlera des ûˋtapes de mise en place de SSH sur les serveurs Web pour effectuer des ûˋchanges sûˋcurisûˋs en cas de nûˋcessitûˋ.
4-2. Dûˋploiement de NTP▲
Dans cette premiû´re partie, nous allons citer les ûˋtapes suivies afin de configurer NTP sur les rûˋpartiteurs de charge dans un premier temps et sur les serveurs Web dans un second temps.
4-2-1. Configuration du serveur NTP▲
-
Installer NTPô : ceci se fait via la commande suivanteô :
Sélectionnez# yum install ntp -
Choisir le Pool de serveurs de temps mondiaux avec lesquels notre serveur doit se synchroniser sur www.pool.ntp.org, plus prûˋcisûˋment surô : www.pool.ntp.org/zone/dz
Sélectionnezserver0.africa.pool.ntp.org server1.africa.pool.ntp.org server2.africa.pool.ntp.org server3.africa.pool.ntp.org -
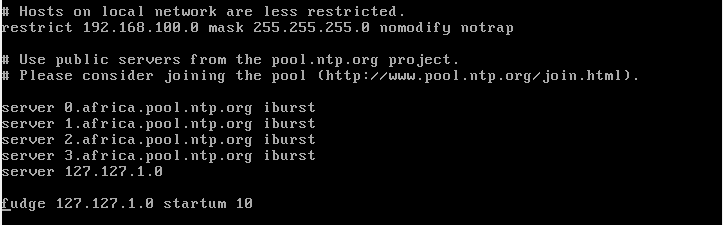
Configurer notre serveur NTP en ûˋditant le fichier de configuration de NTPô : /etc/ntp.conf comme suitô :
- Ajouter le pool de serveurs mondiaux correspondant û notre rûˋgion (Algûˋrie) pour que notre serveur se synchronise avec ces derniers.
- Ajouter la directive fudge 127.127.1.10 stratum 10 constitue un serveur fictif en guise d'IP fallback, au cas oû¿ la source de temps extûˋrieure deviendrait momentanûˋment indisponible. En cas d'indisponibilitûˋ du serveur distant, NTP continuera û tourner en se basant sur ce fonctionnement-lû .
- Autoriser les clients de notre rûˋseau û envoyer des requûˆtes de synchronisation û notre serveur en ajoutant la ligne suivanteô :
restrict 192.168.1.0 netmask 255.255.255.0 nomodify notrap|
|
-
Activer le service NTP comme suitô :
Sélectionnez# chkcong ntpd on# service ntpd start -
Pour vûˋrifier que NTP est bien activûˋ sur le serveurô :
Sélectionnezservice ntpd status - Vûˋrifier la synchronisation de notre serveur avec les serveurs mondiaux de notre rûˋgionô : ntpq -p et date -R pour afficher la date courante du systû´me.
|
|

Remarque 1ô : la synchronisation se fait de maniû´re automatique chaque 64ô s par dûˋfaut, mais si toutefois on veut une synchronisation instantanûˋe, il est possible d'envoyer une requûˆte manuellement au pool de serveurs comme suitô :
ntpdate -q 0.africa.pool.ntp 1.africa.pool.ntp.org4-2-2. Configuration des clients NTP▲
- Installer NTPô : de la mûˆme maniû´re que sur le serveur NTP.
-
Ajouter les load balancers comme serveur NTP dans le fichier de configuration /etc/ntp.conf des serveurs Web pour que ces derniers les considû´rent comme leurs masters et se synchronisent avec eux comme suitô :

-
Activer le service ntpd sur les serveurs Web de la mûˆme maniû´re que sur les rûˋpartiteurs de charge.
- Vûˋrifier le bon fonctionnement de la synchronisation de la mûˆme maniû´re que sur les serveurs NTP.
5. Dûˋploiement de Ganglia▲
La mise en place du suivi temps rûˋel de notre Cluster avec Ganglia se fait en suivant les ûˋtapes ci-dessousô :
5-1. Configuration du néud maûÛtre▲
Dans notre cas, les néuds maûÛtres sont les deux load balancers qui rûˋcupûˋreront les donnûˋes envoyûˋes par les serveurs Web pour les synthûˋtiser sous forme de graphes et statistiques et auxquels on pourra accûˋder via lãinterface Web offerte par Ganglia et naviguer entre les diffûˋrents néuds de notre cluster pour en ûˋvaluer les performances, analyser les rûˋsultats obtenus, dûˋtecter un dysfonctionnement si toutefois il y en a un, etc. La mise en place de Ganglia sur nos deux load balancers se fait de la maniû´re suivanteô :
-
Installer Ganglia et ses prûˋrequisô :
Sélectionnez# yum update && yum install epel-release# yum install ganglia rrdtool ganglia-gmetad ganglia-gmond ganglia-web -
Configuration de lãauthentification û lãinterface Web de Gangliaô : pour cela, nous avons utilisûˋ lãauthentification de base offerte par Apache. Tout dãabord, on commence par crûˋer un utilisateur avec comme nom dãutilisateur ô¨ô gangliaô ô£ et un mot de passe choisi, ces informations seront stockûˋes dans un fichier de configuration dãApache /etc/httpd/auth.basic. Voici la commande permettant de crûˋer cet utilisateurô :
Sélectionnez# htpasswd -c /etc/httpd/auth.basic ganglia -
Puis on tapera deux fois le mot de passe. On peut vûˋrifier le contenu du fichier dãauthentification dãApache comme suitô :
Sélectionnezcat /etc/httpd/auth.basic -
Il faut maintenant modifier le contenu du fichier de configuration /etc/httpd/conf.d/ganglia.conf pour indiquer essentiellement le nom dãutilisateur et le fichier contenant le mot de passe, comme suitô :
SélectionnezAlias /ganglia /usr/share/ganglia<Location /ganglia>AuthType basic AuthName"Ganglia web UI"AuthBasicProvider#leAuthUserFile"/etc/httpd/auth.basic"Require user ganglia</Location> -
Configuration des sources de donnûˋes de Gangliaô : pour cela, nous indiquer le nom de notre Grid, qui sera dans ce cas ô¨ô Clusterô ô£ ainsi que le nom de notre Cluster pour que ce dernier puisse ûˆtre identifiûˋ de faûÏon unique, ici ce sera ô¨ô Serversô ô£. Puis, nous prûˋciserons notre néud maûÛtre en indiquant son interface accessible de lãextûˋrieur, ici ce sera lãadresse externe de notre load balancer, dans notre cas ce sera 192.168.43.9 pour LVS et 192.168.43.10 pour HAProxy. Enfin, nous indiquerons nos néuds source de donnûˋes qui sont nos diffûˋrents serveurs Web. Cette configuration se fait au niveau du fichier /etc/ganglia/gmetad.confô :

-
Configuration du Cluster et des flux dãûˋchanges entre les diffûˋrents néudsô : pour cela, nous ûˋditons le fichier /etc/ganglia/gmond.conf comme suitô : on dûˋfinit tout dãabord notre Cluster. On configure ensuite lãenvoi et la rûˋception via UDP en spûˋcifiant le port dãûˋcoute ici ce sera le port UDP 8649 sur le localhost (oû¿ se trouve Ganglia), voici le contenu devant figurer dans le fichier de configurationô :
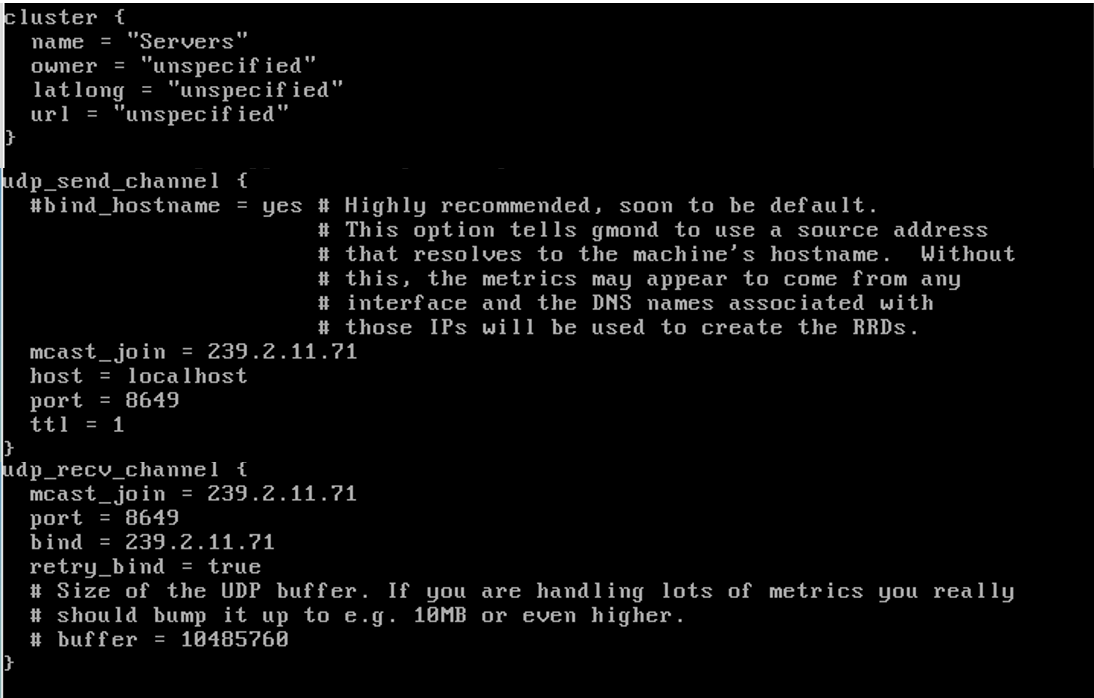
-
Autoriser les scripts PHP exûˋcutûˋs par Apache û se connecter au rûˋseau grûÂce û la commande suivanteô :
Sélectionnez# setsebool -P httpd _can_network_connect 1 -
Changer le port dãûˋcoute dãApache pour quãil ûˋcoute le port 8080 par exemple au lieu de 80 en remplaûÏant Listen 80 par Listen 8080 dans /etc/httpd/conf/httpd.conf, car HAProxy et/ou LVS ûˋcoutent dûˋjû le port 80.
- Activer les services gmond, gmetad et apache sur le load balancerô :
# systemctl restart httpd gmetad gmond
# systemctl enable httpd gmetad httpd5-2. Configuration des néuds source de donnûˋes (Serveurs Web)▲
-
Installer Ganglia gmod sur les serveurs Web. Ceci permettra aux serveurs de transmettre leurs informations au néud maûÛtreô :
Sélectionnez# yum update && yum install epel-release# yum install ganglia rrdtool ganglia-gmond -
Configuration de gmondô : cela se fait en ûˋditant le fichier de configuration /etc/ganglia/gmond.conf de sorte que la partie Cluster soit identique û celle configurûˋe sur le néud maûÛtre, les seuls changements se font au niveau de la configuration des ûˋchanges UDP, voici le contenu du fichier de configuration aprû´s modificationô :
- Activer le service gmondô :
# service gmond start6. Dûˋploiement de SSH▲
-
Installer SSH sur les serveurs Webô :
Sélectionnez# yum install openssh - Activer le service SSH sur les serveurs Webô :
# service sshd start7. ûtude comparative▲
7-1. Introduction▲
Dans cette premiû´re partie de la troisiû´me phase du projet, nous allons effectuer un ensemble de tests afin dãûˋvaluer la qualitûˋ du cluster mis en place selon la nature de lãapplication û laquelle il est dûˋdiûˋ. Puis nous ûˋvaluerons chacune des deux solutions de rûˋpartition de charge proposûˋe, HAProxy et LVS, et nous effectuerons une ûˋtude comparative qui nous permettra de choisir la solution la plus adaptûˋe dans notre cas, celle qui offre le plus de performance et qui rûˋpond le mieux aux attentes. Ce document sera structurûˋ de la maniû´re suivanteô : nous dûˋcrirons en premier lieu lãensemble des tests û effectuer puis nous passerons û lãanalyse et interprûˋtation des rûˋsultats qui nous permettront dãeffectuer une ûˋtude comparative entre les deux solutions de LB pour enfin conclure avec le choix de la solution la plus performante.
7-2. Description des tests û effectuer▲
7-2-1. Tester lãapplication dûˋveloppûˋe▲
Effectuer un ensemble de tests afin de vûˋrifier le bon fonctionnement de lãapplication simulant lãopûˋration BAC en dûˋroulant les cas dãutilisation les plus importants de cette application et montrer que celle-ci rûˋpond totalement aux besoins exprimûˋsô : authentification avec nom dãutilisateur et mot de passe, redirection vers la page des rûˋsultats puis dûˋconnexion de lãutilisateur.
7-2-2. Tester la rûˋpartition de charge et ûˋvaluer les performances▲
Trois algorithmes de rûˋpartition de charge seront testûˋs sur chacun des serveurs LBô : HAProxy et LVS puis, les rûˋsultats obtenus avec chaque algorithme seront analysûˋs afin de choisir celui qui est le plus adaptûˋ selon les ressources consommûˋes, les performances atteintes, les caractûˋristiques de notre application, etc. On conclura les tests avec une interprûˋtation des rûˋsultats sur lesquels sera basûˋe notre ûˋtude algorithmique pour chaque solution de maniû´re indûˋpendante. Enfin, une comparaison entre les rûˋsultats obtenus avec lãalgorithme retenu sur chaque LB et comparer ensuite les deux solutions obtenuesô : rûˋpartition de charge avec LVS et HAProxy.
Les tests se dûˋrouleront de la maniû´re suivanteô :
- Tester en premiers lieux lãalgorithme Round Robin sur les deux serveursô : utiliser les rûˋsultats obtenus avec RR comme rûˋfûˋrence (ce dernier ûˋtant lãalgorithme trivial ou ô¨ô traditionnelô ô£ de rûˋpartition de charge faisant en sorte de distribuer les requûˆtes de faûÏon ûˋquitable sur lãensemble des serveurs, peu importe leur hûˋtûˋrogûˋnûˋitûˋ). Ceci nous permettra de trancher entre les deux autres algorithmes proposûˋs pour chacune des deux solutionsô : LVS et HAProxy.
- Tester deux algorithmes choisis sur LVSô : les algorithmes choisis sont le Weighted Least-Connection et le Shortest Expected Delay. Le premier a ûˋtûˋ proposûˋ, car il prend en considûˋration les performances des serveurs grûÂce aux poids attribuûˋs û chaque serveur ce qui nous permettra de rûˋpartir les requûˆtes sur les serveurs selon leur capacitûˋ. De plus, ce dernier se trouve ûˆtre dynamique, cãest-û -dire quãil ajuste la rûˋpartition de charge en temps rûˋel selon lãûˋtat actuel du cluster en calculant le nombre de connexions sur chaque serveur puis selon son poids, dûˋcide de la maniû´re de rûˋpartir les requûˆtes, le serveur ayant le plus petit rapport nombre de connexions actives sur son poids sera sûˋlectionnûˋ. Pour le deuxiû´me algorithme, le choix sãest portûˋ sur celui-ci, car il est dynamique, basûˋ sur les poids assignûˋs aux serveurs ainsi que le dûˋlai de rûˋponse calculûˋ selon le rapport (nombre de connexions + 1) / poids du serveur en prenant en considûˋration la nouvelle connexion.
- Tester deux algorithmes choisis sur HAProxyô : les algorithmes choisis pour HAProxy sont Weighted Round Robin et Weighted Least Connections. Le premier fonctionne exactement comme RR sauf quãil prend les poids attribuûˋs aux serveurs en considûˋration, cãest-û -dire quãil essayera au mieux de rûˋpartir la charge de maniû´re ûˋquitable sur les diffûˋrents serveurs selon leur capacitûˋ et performance. Le taux de requûˆtes envoyûˋes û chaque serveur sera donc diffûˋrent, mais lãefficacitûˋ du cluster sera meilleure, car on exploitera au mieux les performances des néuds. Pour le deuxiû´me algorithme, la justification est exactement la mûˆme que pour LVS.
- û chaque fois, afficher les rûˋsultats obtenus sous forme de graphes, courbes, etc. Analyser et interprûˋter les rûˋsultats obtenus pour effectuer le choix de lãalgorithme le plus adaptûˋô : faire varier le nombre de requûˆtes simultanûˋes (10ô 000, 20ô 000, 30ô 000, 40ô 000, 50ô 000) et utiliser les graphes et statistiques gûˋnûˋrûˋs par Ganglia afin de rûˋcupûˋrer la consommation des ressources (CPU et RAM essentiellement), le nombre de requûˆtes reûÏues et le nombre de requûˆtes traitûˋes, le temps dãexûˋcution des requûˆtes (temps total, temps moyen, etc.). Utiliser Apache Jmeter pour les tests de performance.
- Comparer les rûˋsultats obtenus avec LVS et les rûˋsultats obtenus avec HAProxy.
Remarqueô : les algorithmes choisis sur chaque LB ont la propriûˋtûˋ dãûˆtre dynamiques ûˋtant donnûˋ la nature de notre application, plusieurs utilisateurs û travers le territoire national seront connectûˋs en mûˆme temps et enverront un nombre important de requûˆtes, les serveurs se retrouveront vite saturûˋs si on se contentait seulement de leur attribuer des poids, ces derniers ûˋtant des valeurs gûˋnûˋralement expûˋrimentales et non exactes, il faut donc un moyen dãadaptation ou rûˋadaptation en temps rûˋel afin de garantir une rûˋpartition de charge de qualitûˋ.
7-2-3. Health checkup des serveurs Backend▲
- Essayer avec un simple algorithme de rûˋpartition de charge, RR û priori, quãeffectivement le health checkup fonctionne sur le load balancer HAProxy, et que ce dernier vûˋrifie que les serveurs rûˋpondent et que si ce nãest pas le cas, ils transfû´reront la requûˆte vers un serveur qui rûˋpond.
- Tester de la mûˆme maniû´re le fonctionnement de Keepalive sous LVS.
- Expliquer ce qui se passe avec lãalgorithme de load balancing choisi pour HAProxyô : faire un test avec un nombre rûˋduit de requûˆtes permettant dãanticiper les serveurs devant ûˆtre choisis et essayer dãûˋteindre lãun des serveurs et vûˋrifier quãeffectivement, la requûˆte est envoyûˋe au prochain serveur qui rûˋpond au critû´re de lãalgorithme choisi.
- Faire de mûˆme avec lãalgorithme choisi pour LVS.
7-2-4. Tester la persistance de session▲
ûtant donnûˋ la nature de notre application (application PHP), la persistance de session est primordiale. Un client qui se connecte une premiû´re fois sur le site pour voir ses rûˋsultats sera dirigûˋ vers un serveur donnûˋ selon la stratûˋgie de rûˋpartition de charge, mais si jamais sa session est perdue (il est par exemple redirigûˋ vers un autre serveur û lãenvoi dãune autre requûˆte), lãutilisateur se retrouvera dûˋconnectûˋ et sa session perdue. Une simple actualisation de la page causera cela, il faut donc faire en sorte que les requûˆtes de cet utilisateur soient toutes envoyûˋes et traitûˋes par le mûˆme serveur que celui de sa premiû´re connexion et ce, pendant une durûˋe fixûˋe par lãadministrateur (Timeout). Pour cela, nous avons utilisûˋ les Sticky Sessions au niveau de HAProxy et la LVS persistence sur LVS. Pour vûˋrifier le bon fonctionnement, nous simulerons lãenvoi de plusieurs requûˆtes û partir de diffûˋrents clients (diffûˋrentes sessions) puis nous essayerons dãactualiser par exemple pour voir que chaque utilisateur reste connectûˋ tant que le timeout fixûˋ nãa pas expirûˋ, nous visualiserons ensuite la correspondance entre les serveurs et les utilisateurs.
7-3. Interprûˋtation des rûˋsultats obtenus▲
Dans ce qui suit, nous allons interprûˋter les rûˋsultats des tests effectuûˋs sur LVS et HAProxy pour les trois algorithmes choisis. û noter que les poids des serveurs sont les suivantsô :
- Serveur 1ô : 10
- Serveur 2ô : 10
- Serveur 3ô : 10
- Serveur 4ô : 20
- Serveur 5ô : 30
- Serveur 6ô : 20
7-3-1. LVS▲
7-3-1-1. Round Robin▲
|
|
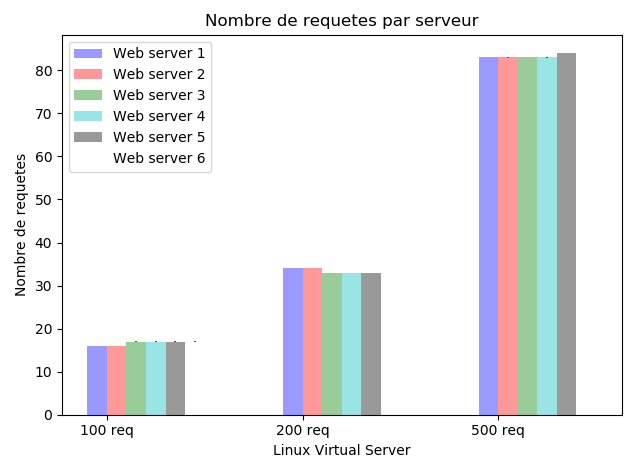
Comme nous pouvons le voir sur le graphe ci-dessus, les requûˆtes sont distribuûˋes uniformûˋment (et de maniû´re cyclique conformûˋment û lãalgorithme Round Robin) sur les diffûˋrents serveurs.
7-3-1-2. Shortest Expected Delay▲
|
|
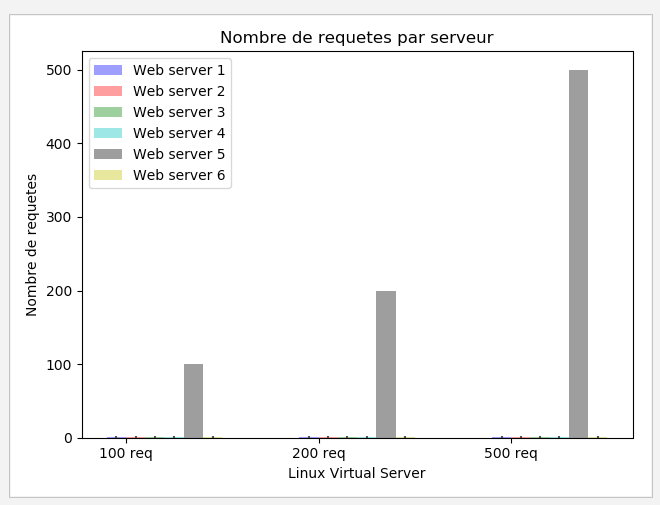
La figure montre que les requûˆtes ont toutes ûˋtûˋ dirigûˋes vers le serveur 5, car il a le poids le plus fort et donc cãest celui qui est susceptible de rûˋpondre le plus rapidement (en dãautres termes celui qui est susceptible dãavoir le dûˋlai le plus court), ceci mûˆme en considûˋrant le nombre de connexions actives, car lãenvoi et la rûˋception des requûˆtes se font en un temps rûˋduit.
7-3-1-3. Weighted Least Connection▲
|
|
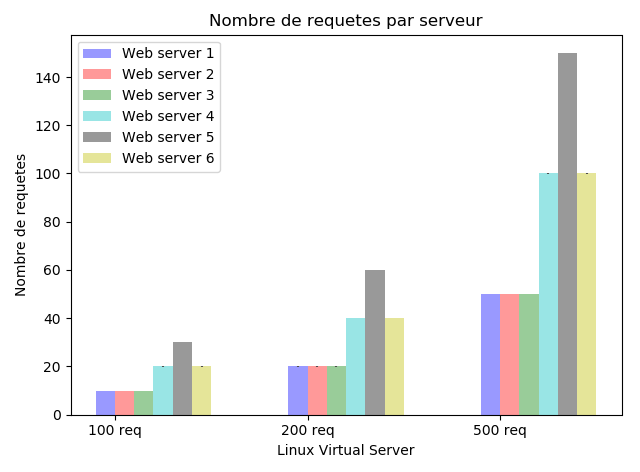
On remarque que les serveurs 1, 2 et 3 ont reûÏu le mûˆme nombre de requûˆtes, de mûˆme pour les serveurs 4 et 6 alors que le serveur 5 a reûÏu un nombre plus ûˋlevûˋ de requûˆtes et ceci est dû£ au nombre de connexions actives en prenant en considûˋration les poids (attribuûˋs relativement aux performances des diffûˋrents serveurs).
7-3-1-4. Comparaison▲
Nous constatons que dans le cas de LVS, lãalgorithme ô¨ô Weighted Least Connectionô ô£ semble ûˆtre le meilleur, et ceci est visible û travers les graphes ci-dessous.
|
|
|
|
|
|

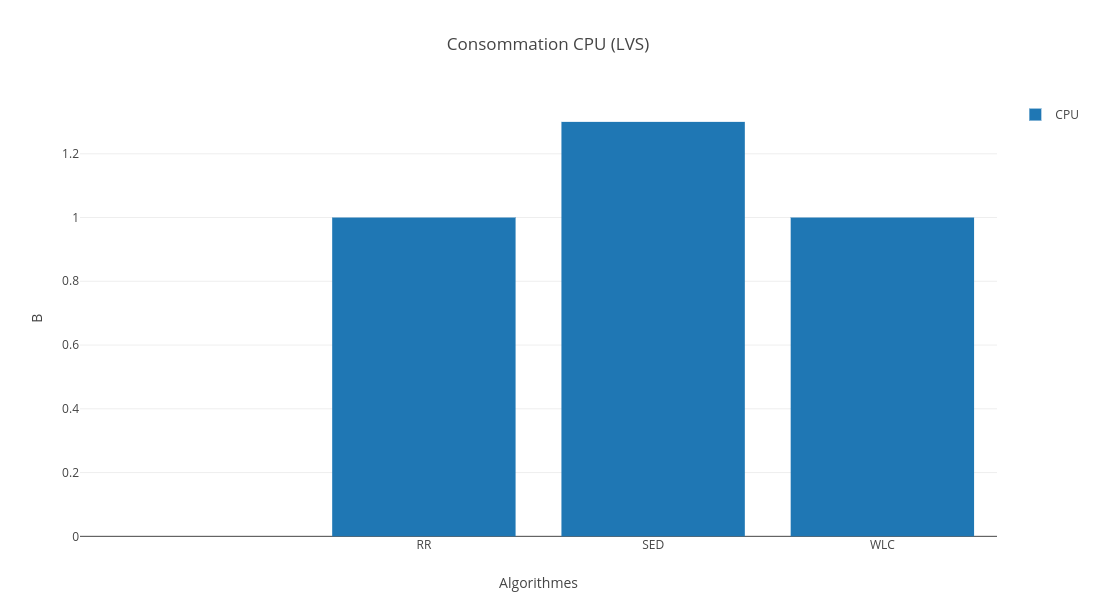
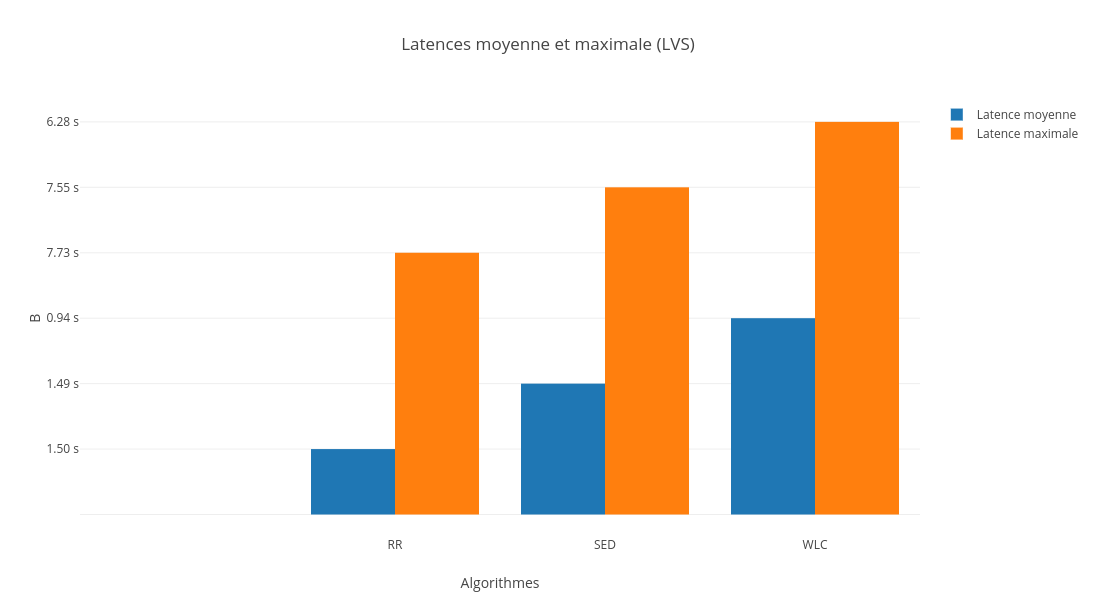
En effet, comme nous pouvons le voir, la latence due û lãordonnancement des requûˆtes entrantes est la plus courte pour le WLC, de mûˆme pour le nombre de requûˆtes traitûˋes par seconde. Ceci peut ûˆtre expliquûˋ par le fait que cet algorithme se base sur deux facteurs qui influent grandement sur les mûˋtriques reprûˋsentûˋes sur le grapheô : le poids ûˋtant un facteur assez reprûˋsentatif des performances du serveur, et le nombre de connexions actives ûˋtant un paramû´tre important puisque les utilisateurs affectûˋs û un serveur peuvent ûˆtre connectûˋs plus longtemps sur celui-ci que les utilisateurs affectûˋs û un autre serveur.
7-3-2. HaProxy▲
7-3-2-1. Round Robin▲
|
|
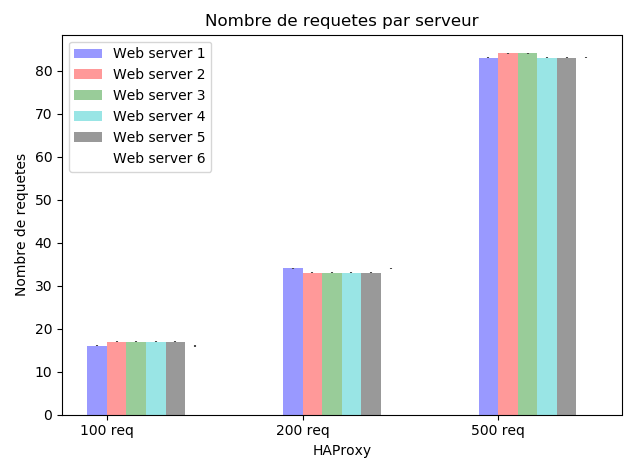
Comme nous pouvons le voir sur le graphe ci-dessus, les requûˆtes sont distribuûˋes uniformûˋment (et de maniû´re cyclique conformûˋment û lãalgorithme Round Robin) sur les diffûˋrents serveurs.
7-3-2-2. Weighted Round Robin▲
|
|
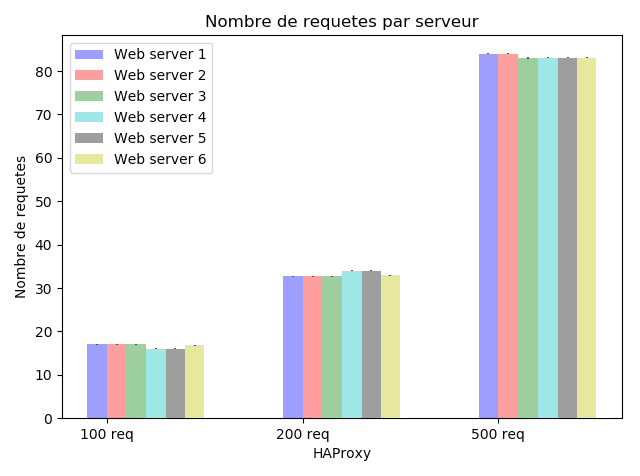
Les requûˆtes sont distribuûˋes de maniû´re cyclique sur les diffûˋrents serveurs en prenant uniquement en considûˋration les poids affectûˋs. Ainsi, le serveur ayant le poids le plus ûˋlevûˋ (Serveur 5 avec le poids 30) a reûÏu le plus de requûˆtes, suivi par les serveurs 4 et 6 qui ont un poids de 20 chacun, ensuite les serveurs 1, 2 et 3 qui ont un poids de 10 chacun.
7-3-2-3. Weighted Least Connection▲
|
|
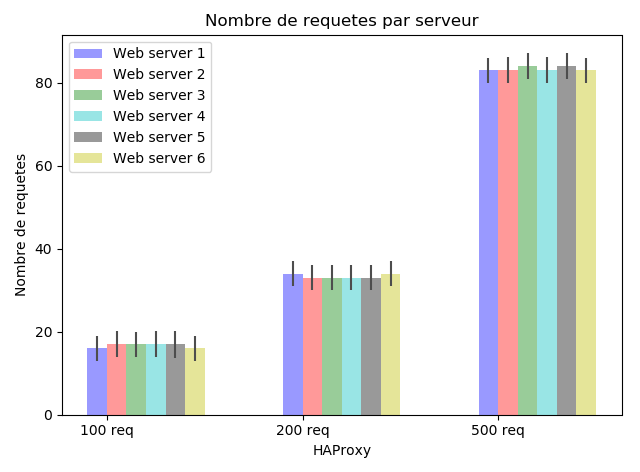
On remarque que les serveurs 1, 2 et 3 ont reûÏu le mûˆme nombre de requûˆtes, de mûˆme pour les serveurs 4 et 6 alors que le serveur 5 a reûÏu un nombre plus ûˋlevûˋ de requûˆtes et ceci est dû£ au nombre de connexions actives en prenant en considûˋration les poids (attribuûˋs relativement aux performances des diffûˋrents serveurs).
7-3-2-4. Comparaison▲
Comme pour LVS, nous constatons que le meilleur algorithme pour HAProxy est le ô¨ô Weighted Least Connectionô ô£.
|
|
|
|
|
|
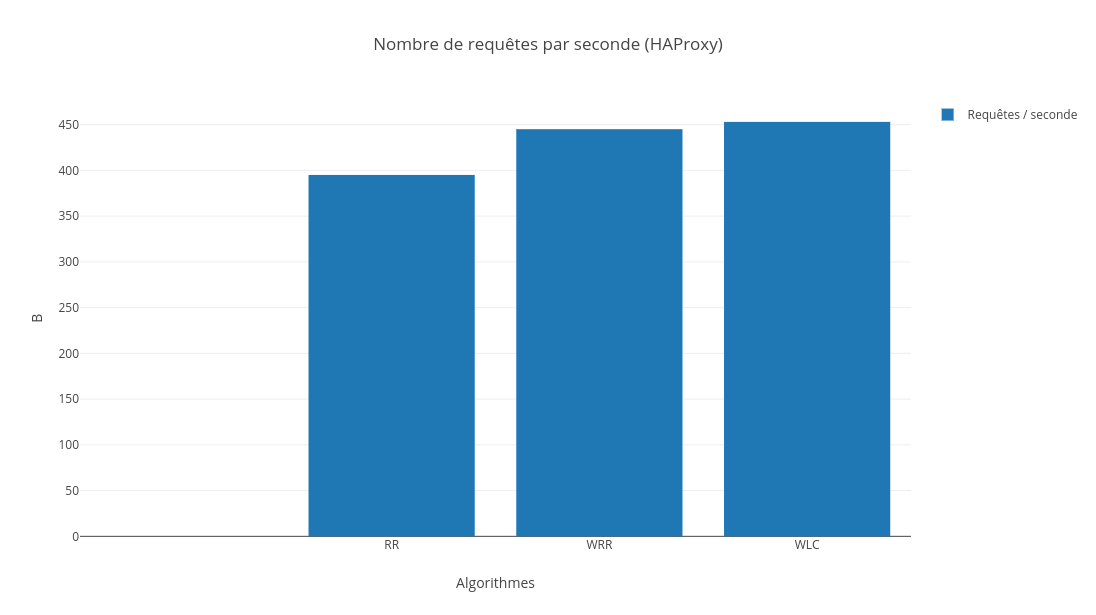
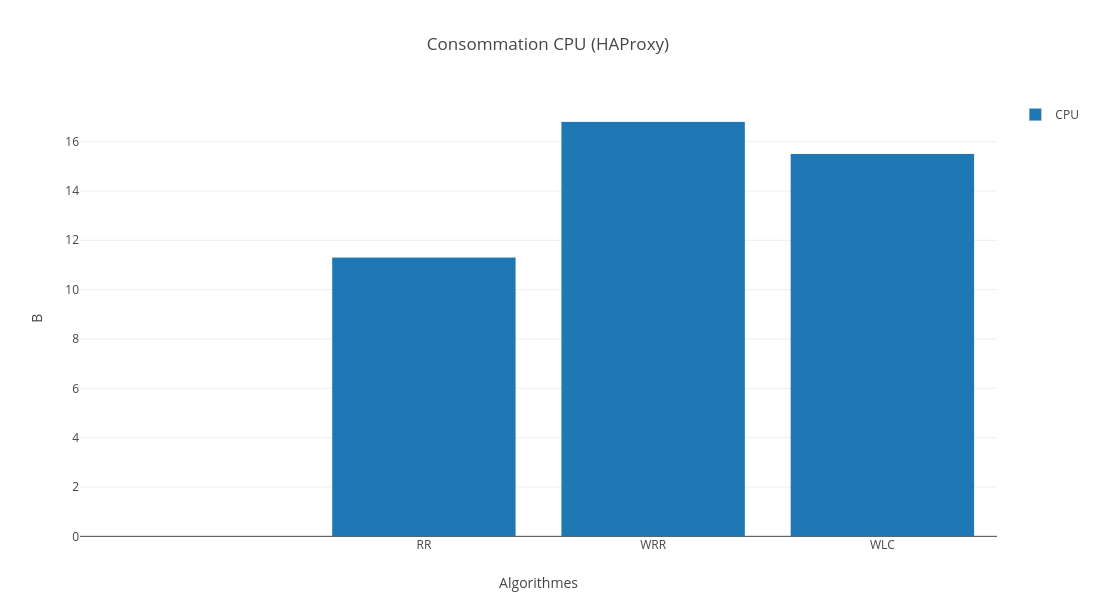
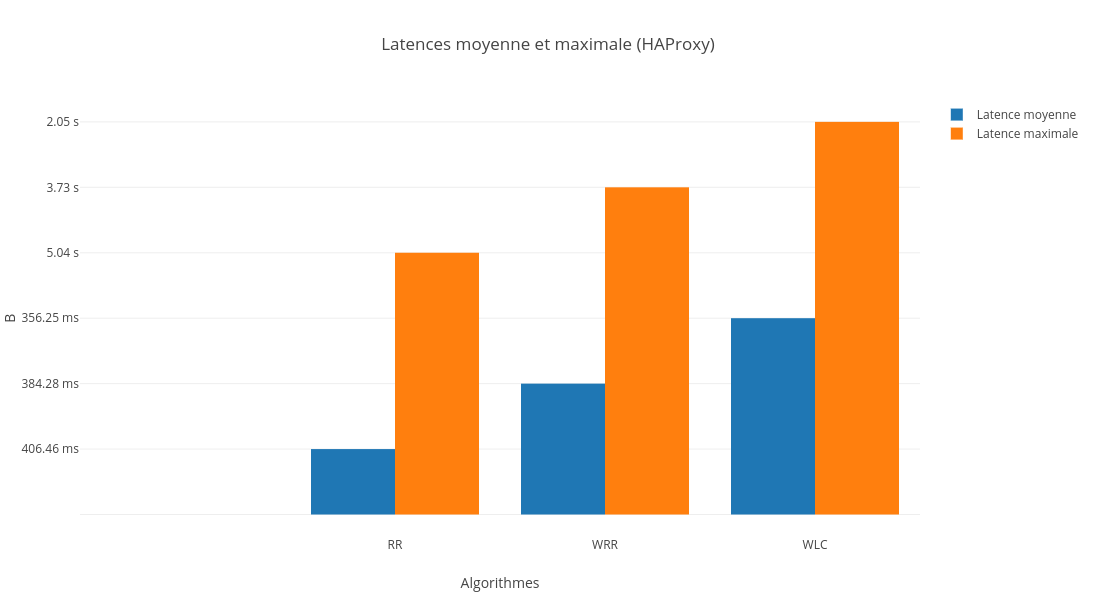
En effet, la latence et le nombre de requûˆtes par seconde sont plus faibles pour le WLC comparûˋ aux autres algorithmes. Quant û la consommation CPU, la diffûˋrence est nûˋgligeable. La justification est la mûˆmeô : les deux facteurs sur lesquels se base WLC (poids et nombre de connexions actives) influent grandement sur les mûˋtriques que lãon a considûˋrûˋes dans notre cas.
7-4. Comparaison entre HAProxy et LVS▲
La finalitûˋ du projet est de comparer entre les deux solutions de Load Balancing que sont LVS et HAProxy dans le contexte de notre application, puis de choisir celle qui rûˋpond le mieux aux critû´res de performance et de haute disponibilitûˋ nûˋcessaires û lãopûˋration Bac. Ce choix est fondûˋ non seulement sur les rûˋsultats des diffûˋrents tests effectuûˋs sur le cluster, mais aussi sur les points forts et les points faibles de LVS et HAProxy que nous avons pu identifier tout au long du projet. Il convient donc de les citer dans ce qui suit.
7-4-1. LVS▲
7-4-1-1. Points forts▲
- Implantation de LVS sur le noyau, ce qui entraûÛne un temps de rûˋponse minimal.
- Nûˋcessite une faible consommation CPU ûˋtant donnûˋ quãil se contente de router les paquets sans examiner leur contenu.
- Installûˋ par dûˋfaut sur Linux.
7-4-1-2. Points faibles▲
- Absence de health checkô : nûˋcessitûˋ dãinstaller et de configurer Keepalived.
- Nûˋcessitûˋ de configurer le load balancer comme ûˋtant la passerelle par dûˋfaut des serveurs backend.
- Dans le cas de LVS NAT, le load balancer peut constituer un goulot dãûˋtranglement si le nombre de serveurs backend dûˋpasse 20.
- La mise û jour de LVS peut entraûÛner la mise û jour du kernel de Linux.
7-4-2. HAProxy▲
7-4-2-1. Points forts▲
- Possibilitûˋ de faire un health check au niveau TCP et au niveau applicatif.
- Diversitûˋ des mûˋthodes pour implûˋmenter la persistanceô : algorithmes dãordonnancement (Hachage de lãadresse source par exemple), concatûˋnation de lãID du serveur avec le cookie dãune application (Le session ID dãune application PHPãÎ), insertion dãun autre cookie, etc.
- Possibilitûˋ dãutiliser des ACL.
- Flexibilitûˋ en termes de configuration.
- Affichage des statistiques sur une interface Web.
- Fonctionnalitûˋ de reverse proxy HTTP.
7-4-2-2. Points faibles▲
- Consommation CPU assez ûˋlevûˋe (relativement û LVS).
- Nûˋcessite des dûˋpendances pour lãinstallation.
7-5. Choix de la meilleure solution▲
En nous appuyant sur les rûˋsultats des tests ainsi que sur les caractûˋristiques des deux logiciels de load balancing, nous pouvons conclure que la solution la plus adûˋquate pour lãopûˋration Bac est HAProxy.
|
|
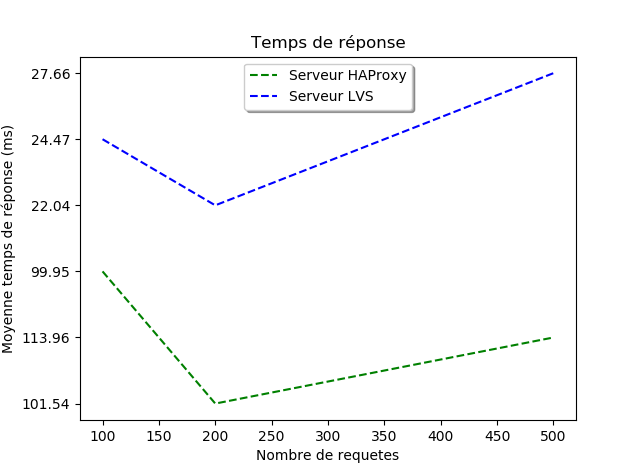
En effet, de par le fait quãil soit entiû´rement dûˋdiûˋ au trafic HTTP, nous avons constatûˋ quãil offrait une plus faible latence (et donc un temps de rûˋponse plus faible) comparûˋ û LVS. Ce dernier, bien quãil ait lãavantage dãûˆtre implantûˋ sur le noyau de Linux, dans notre cas cela ne reprûˋsente pas un point fort puisque les serveurs sont sur des VM, donc il y a une couche additionnelle de virtualisation qui fait quãon ne peut profiter pleinement de LVS.
Par ailleurs, si lãon considû´re lãaspect consommation CPU, lãapplication ne nûˋcessite pas une grande puissance de calcul, donc mûˆme si HAProxy demande plus de ressources CPU que LVS, la consommation ne dûˋpasse pas les 20ô % ce qui est acceptable.
Dãautre part, HAProxy est trû´s flexible et propose un large ûˋventail de fonctionnalitûˋs, il permet en outre dãoffrir un certain niveau de sûˋcuritûˋ grûÂce au reverse proxying et aux ACL. Il offre ûˋgalement des outils de validation HTTP (permettant de vûˋrifier si les requûˆtes sont conformes aux standards HTTP) et une protection au niveau applicatif contre les attaques DDoS. Cet aspect, bien que nous ne lãayons pas dûˋtaillûˋ dans le projet, constitue un rûˋel avantage.
- Par consûˋquent, dans notre contexte, nous pouvons dire que HAProxy est la solution la plus adaptûˋe.
8. Conclusion▲
Ce projet a ûˋtûˋ rûˋalisûˋ par Amina, Manel Aghiles, Mehdi, Mohamed, et moi-mûˆme.
8-1. Bibliographie▲
[1] HAProxy Starter Guideô : http://cbonte.github.io/haproxy-dconv/1.9/intro.html.
[2] LVS Documentationô : http://www.linuxvirtualserver.org/Documents.html.
[3] LVS Wikiô : http://kb.linuxvirtualserver.org/wiki/.
[4] How to install and configure HAProxy on CentOS 6, fûˋvrier 2015ô :
https://idroot.net/tutorials/install-configure-haproxy-centos-6/.